Using Smart Response Compliance in Agent Console and Care Console to ensure brand protection
Updated
How Sprinklr’s AI-powered response compliance ensures that each brand response adheres to appropriate business communication protocols and flags the non-compliant responses.
Engaging on different social/email channels daily requires a tricky balance between maintaining an authentic voice and following the brand guidelines and compliance restrictions. To support customer support teams and brand managers, Sprinklr provides AI-driven Smart Response Compliance to ensure that each brand response complies with established standards. A yellow flag is generated if your response does not comply with any of these categories to help you manage risk and avoid crises for your brands. Agents can also provide feedback on compliance checks to make them more accurate.
Note:
|
Categories of Response Compliance
Default Parameters - The Response Compliance model flags the responses on the basis of the following default parameters:
Biased Content: This check flags the responses if the response is discriminatory along the lines of race/religion/gender/age/person or has opinionated content that could be controversial in nature.
Profanity: This check flags the responses when the response contains abuses, slurs, and/or adult content.
Relevance: This check flags the response based on its relevance – whether the response is relevant based on the prior conversation.
Tonality: This check flags the response on the basis of its tone i.e when the response shows aggressiveness or lacks warmth and empathy.
Customized Parameters - To get the following compliance checks enabled, please reach out to support at tickets@sprinklr.com.
Incorrect Salutation: The salutation at the starting of the conversation should have a personalisation while addressing the customer.
Hey user, Hi customer - Wrong ❌
Hi Cathy, Hello Mr. Smith - Correct ✅
Business Jargon/Abbreviations: The industry specific jargons and business words are difficult for customers to understand and will be flagged.
Hi, your dob is mentioned as 12/07/2001 - Wrong ❌
Hi, your date of birth is mentioned as 12/07/2001 - Correct ✅
Empathy: A distressed/frustrated customer expects some sort of empathy in the agent’s response, so this flag will be shown to the agent when the customer is distressed and the agent has shown no empathy in their response.
You're not supposed to do it that way - Wrong ❌
I understand what you’re going through - Correct ✅
Any other parameters specific to the business use case.
Why Sprinklr?
The accuracy of our model ranges from 80% to 90%.
The model works equally well for all industries.
We also provide customized models to suit the specific requirements of a client belonging to a particular industry vertical.
We constantly monitor and retrain our model on new datasets. We have relevant datasets from all industries to easily retrain the model so that the accuracy never falls below the desired level.
To check Response Compliance in Care Console
Click the New Tab icon
. Under the Sprinklr Service tab, click Care Console within Resolve.
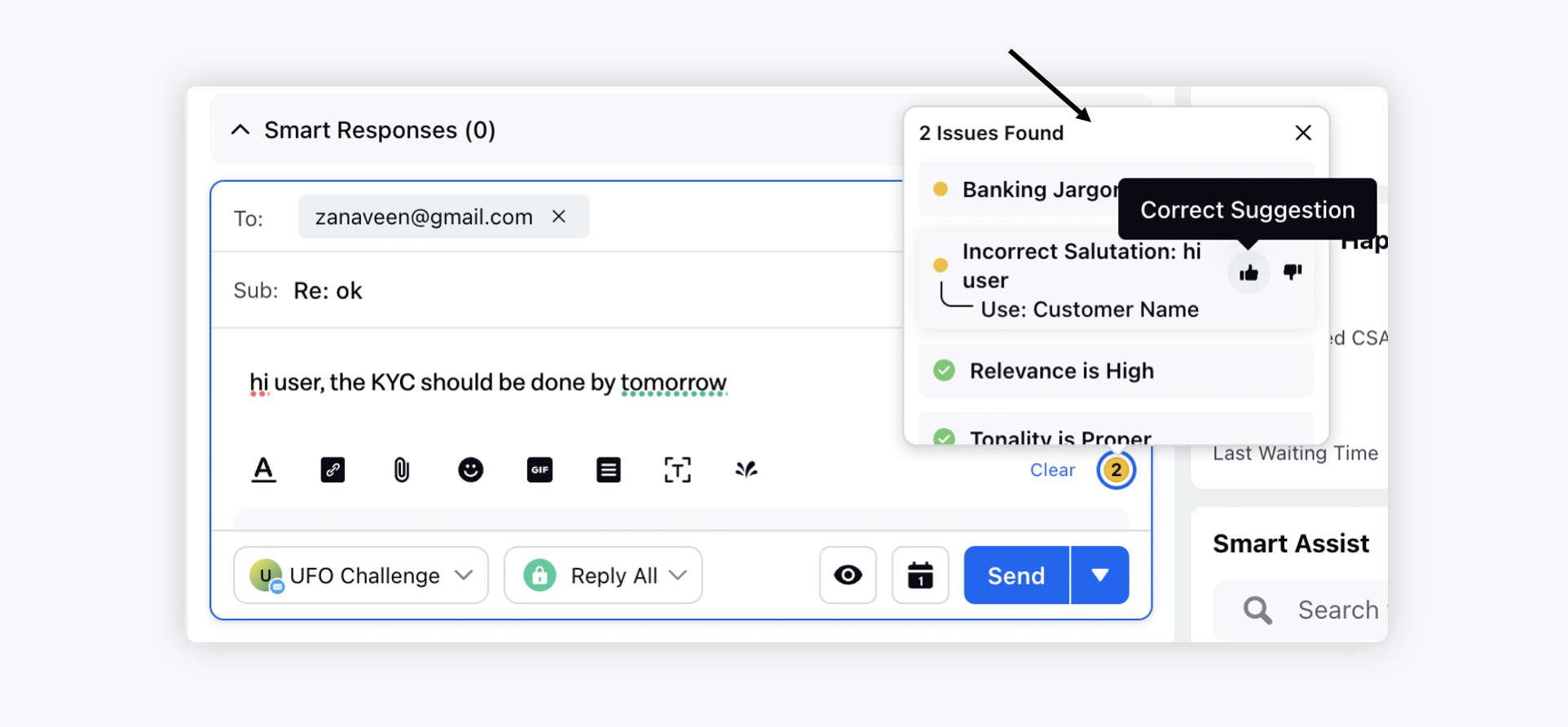
Select a case/message that you want to reply to. While writing a reply in the reply box, you will see Compliance Issues, if any. If the response abides by all the above parameters, it will generate a green tick mark. You can click the tick mark to know more about the compliance check on the given response.

If the response is non-compliant on any of the parameters, it will generate a yellow flag. By clicking on it, you can view the compliance parameters that are violated in the response. As per the suggestions given by the model, you can make the changes to your response before publishing.
The flags are generated by an AI model which requires training and continuous updation to incorporate brand-specific identities. You can give feedback if something incorrect is flagged to retrain the model for further compliance checks. Click the Thumbs up/down icon alongside the parameter to provide the feedback. Click the Dismiss (x) icon to close the compliance box.
Note: Once there is a sufficient number of feedback responses received, we will internally do a quality check on the feedback received and re-train the model.
Note: The publishing of a message is not stopped if it’s non-compliant. The compliance check only generates a flag as a warning. In case, you want to stop publishing a non-compliant response or route it through an approval process, you can leverage the Rule Configuration.
Similarly, you can use the reponse compliace in Agent Console.
To create a rule for non-compliant replies
Create a new Outbound rule in Rule Engine.
Under Conditions Applies To "The properties of the outbound Message", add the condition as desired, e.g., Is Biased, Is Profane, Is Irrelevant, Is Improper Tone.
You can add actions as per your need. This can be either setting an approval path where you set up an approval mechanism for the outbound replies or blocking such replies.
