





Transform CX with AI at the core of every interaction
Unify fragmented interactions across 30+ voice, social and digital channels with an AI-native customer experience platform. Deliver consistent, extraordinary brand experiences at scale.




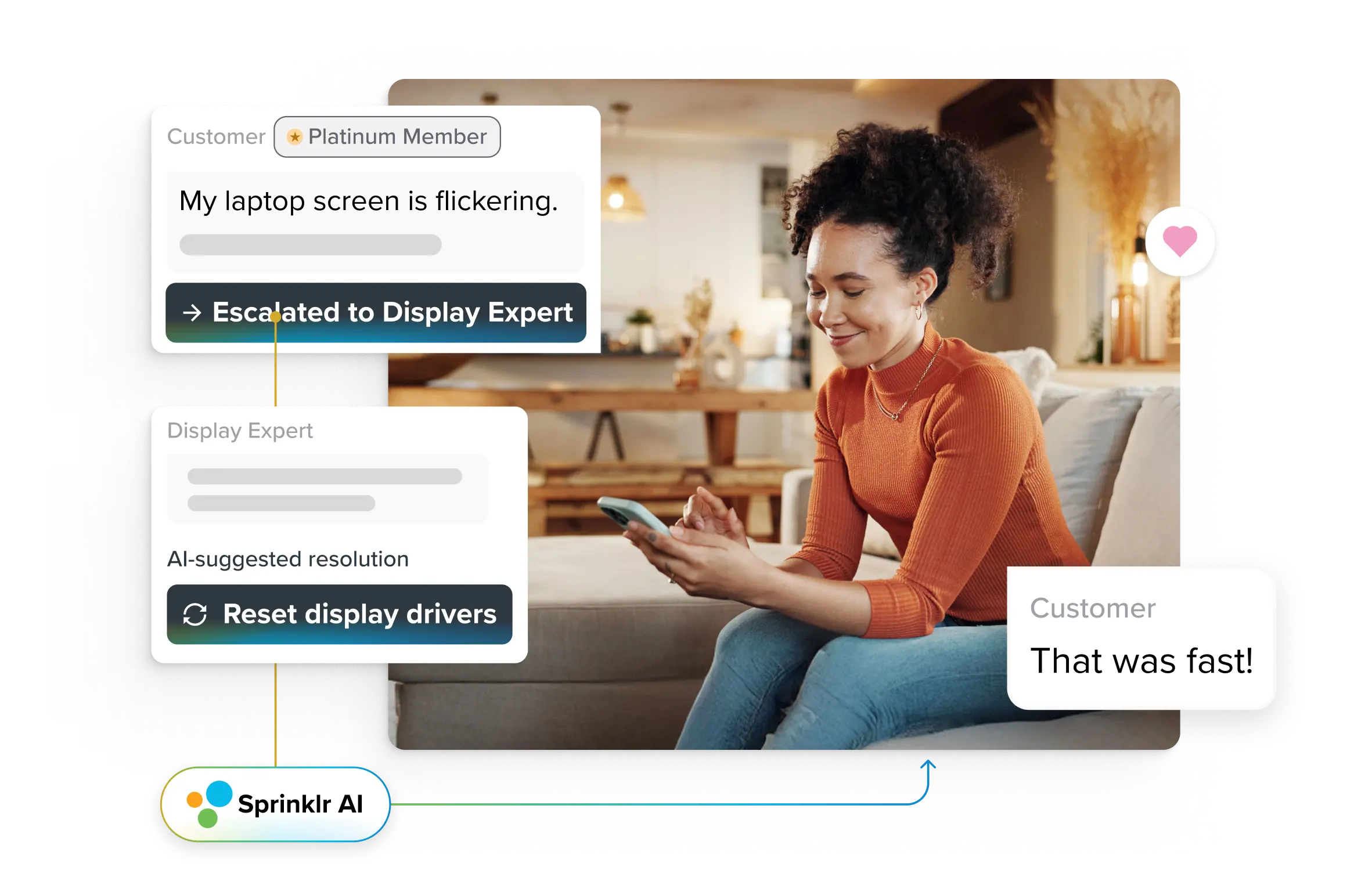
Customer Service Problem Solving: What Top Brands Do Differently


Most brands think great customer service means resolving tickets faster. But the truth is, speed stopped being a differentiator the moment generative AI became mainstream. Today, fast is table stakes. What separates the leaders is how they stop problems before they start.
Top brands like Google and OpenAI don’t wait for customers to report issues. They monitor signals across every channel, detect anomalies early, and fix issues before they ever hit the queue. That’s the real competitive edge: engineered prevention, not heroic recovery.
In this article, we break down this approach, including strategies, real-world business examples and customer service problem-solving tips your enterprise can use to match the pace of the strongest players in your industry.
The anatomy of a customer problem
Every customer issue carries four layers beneath it:
- Signal: The earliest, often subtle indication that something might be off. Think a jump in search queries for a feature name, rising complaints on social forums, or unusual patterns in usage logs.
- Symptom: The visible problem customers report, like errors, delays, failed transactions, confusing flows or broken links.
- Pattern: When similar symptoms repeat across customer segments, channels, device class or time window; indicating a systemic issue rather than an isolated case.
- Root cause: The underlying factor creating the pattern — a flawed customer service workflow, failing integration, policy gap, or technical bottleneck.
Average organizations operate at layers 2-3: they fix the immediate symptom and document a workaround. Then the problem reappears: volumes rise, agents burn out, and leaders assume the process is “fixed” because responses were fast, but the system stays broken.
Top brands try to act at layer 1, because the earlier you intervene, the fewer customers experience the symptom, and the fewer tickets your team has to absorb.
Consider what happened with Netflix in November 2025: as the first four episodes of Stranger Things Season 5 rolled out, service disruptions spiked. Thousands of reports were logged from users in the U.S. and beyond, as streaming froze or connection errors appeared right at the premiere moment. The spike in customer complaints hit before Netflix publicly acknowledged an underlying service issue, and service was restored within minutes. The episode underscored what happens when a brand reacts at the symptom stage rather than catching early signals and acting ahead of load spikes.
Top brands work at the signal level. They monitor early signals — logs, synthetic tests, usage analytics, and give support teams tools to spot emerging patterns while they’re still small.
For example, ahead of Black Friday-Cyber Monday, Shopify ran full-scale synthetic buyer simulations using its internal “Genghis” load runner. These tests exposed ETL bottlenecks, API memory spikes, and load-balancer limits before real shoppers encountered them. By fixing these issues in advance, it prevented widespread checkout failures, turning a potential crisis into an internal exercise with zero customer disruption.
🔖Basics First: What is Proactive Customer Service?
What top brands do differently to solve customer problems
As CX expert Shep Hyken notes, “When it comes to customer service and CX, customers continue to be smarter.” They can instantly compare experiences across industries and know when brands cut corners. In this environment, waiting for symptoms is a losing strategy. Problem-solving today is about detecting issues early, diagnosing them accurately, and preventing repeat issues altogether. The following strategies illustrate how leading brands approach problems at a deeper and more systematic level.
1. Run a formal “problem lifecycle” system
Elite teams do not treat issues as isolated tickets. They use a defined problem lifecycle where every problem progresses through structured stages that reveal the underlying issue rather than its surface symptoms.
Here’s what that looks like operationally:
- Capture: Identify incoming signals — a spike in “payment failed” messages from iOS users.
- Classify: Apply structured metadata like device type, payment method, error code.
- Confirm pattern: Analyze trends to see if this affects a cohort or rollout version, for example, volume trends indicating that the issue affects only new iOS users on version 17.4, not Android or web users.
- Assign ownership: Hand off systemic issues to a dedicated team. For e.g., the payments engineering team, not support, is formally assigned ownership to fix the issue.
- Solve: Engineering identifies a compatibility glitch with Apple’s in-app purchase API and applies a fix.
- Validate: Support and product teams monitor case volume and confirm a sharp drop in related issues.
- Publish learnings: The incident is documented in an internal knowledge system, allowing future teams to understand the root cause and solution.
For instance, OpenAI updates its public troubleshooting guides and technical documentation whenever new patterns emerge. This keeps users informed and reduces repeat tickets before they appear.
This approach transforms problem-solving into a predictable, repeatable system, rather than a reactive workflow that repeatedly surfaces the same issues. It also fosters proactivity in customer service, enabling teams to resolve the problems before they escalate and deliver a more stable and trustworthy customer experience.
🔖Also Read: How to Empower Your Whole Organization in Problem Solving
2. Enforce a “no orphan problems” policy
Top brands refuse to let recurring issues linger without taking ownership. When a problem shows up repeatedly, even slightly, it is assigned to a specific business owner outside the support team. This shifts accountability from “handling complaints” to “removing the source of complaints.”
Here’s an example of how this plays out:
- The support team flags a recurring login issue that has appeared for three consecutive weeks.
- Instead of asking agents to refine scripts or macros, the issue is assigned to the Identity or Platform Engineering lead.
- That owner is measured on reducing cases, not ticket handling speed.
- Cross-functional reviews track whether the issue is shrinking, stabilizing, or growing.
This is essentially how service operations leaders function in mature CX organizations. They act as the connective tissue between support and the rest of the business.
💡Pro Tip: The job of such ownership-taking professionals is to route every recurring problem to the right functional owner, ensure accountability is enforced and verify that fixes actually reduce ticket volume. To elevate their efforts, invest in an AI-powered supervisor console.
It offers capabilities for omnichannel case monitoring, performance monitoring, operations management, and agent upskilling, so challenges are addressed at their root to prevent them from emerging.

3. Use forensic tagging on every case
Your enterprise must treat every support interaction as a data point. Instead of generic tags like “billing issue” or “login problem,” apply forensic tagging, structured, high-resolution diagnostic labels that reveal patterns within days instead of quarters. This gives teams a microscopic view into where failures originate.
A vague tag like “payment failed” tells you almost nothing. But a forensic tag like “iOS17.4 → WalletPay → error 406 → after profile update → high frustration → suspected token mismatch” tells engineering exactly where to look.
This level of context helps engineering teams pinpoint failures faster and reduces investigation time. Precision tagging bridges the gap between frontline data and product fix cycles.
💡Pro Tip: To make tagging more convenient for your CX team, invest in a conversational analytics software.
Modern ones come with built-in features for root-cause analysis that automatically identify critical contact drivers impacting your key call center KPIs. It also creates precision tags and offers role-specific insights with AI recommendations for improving them.
Additionally, these tools can analyze past conversations using unsupervised AI clustering to identify your top contact drivers, analyze customer sentiment, and automate effortless action.

🔖Related Read: Top 9 Customer Experience KPIs to Monitor
4. Embed support directly into product and policy sprints
Integrate support leaders into sprint planning, so frontline insights inform backlog decisions and prevent repeat issues from being shipped again. This creates a shared and accurate view of customer friction across support, product, and engineering.
How this works in practice:
- A support lead participates in sprint planning with a weekly evidence packet:
- Repeat-ticket heatmaps
- Sentiment trend shifts
- API error clusters
- Breakpoints in customer journeys (where customers drop or loop)
- Releases touching fragile flows (billing, login, identity, compliance) require pre-release rehearsals:
- Replay historical failure cases through the new flow
- Validate observability, not just QA pass/fail
- Success metrics include: feature adoption + ticket reduction for the related driver within 14-30 days.
This turns sprint planning into a customer protection layer, ensuring preventable issues never reach the customer.
5. Run quarterly “complexity audits”
One of the biggest mistakes enterprises make is assuming more automation will fix a broken experience. In reality, most recurring customer problems come from complexity.
High-performing organizations treat complexity as measurable risk and periodically audit:
- Policy steps customers frequently abandon or misinterpret.
- UX flows where error rates spike at the same step for months.
- Form fields or verification tasks that stall conversion.
- Scripts or compliance rules that trap agents in rigid paths.
- Multi-channel journeys where context drops and effort increases.
💡Pro Tip: Analyzing omnichannel and fragmented customer journeys can be challenging. Use a customer service analytics and reporting platform with built-in journey analytics.
It tracks customer experience across every touchpoint, monitors end-to-end behavior and applies multi-level drilldowns to reveal where friction originates. This helps you simplify the proper steps before they become expensive support problems.

🔖Recommended Read: Customer Journey Strategy in 2025: How to Create (+Tips)
6. Use AI for investigation and correlation
Most enterprises still treat AI as a response engine, but top brands use it as an investigation engine.
Instead of just deflecting tickets, AI clusters similar cases, identifies shared signatures (device/version/time window/error codes), and routes a root-cause candidate to the team that can validate it.
Take Uber, for example. It showcases how Sprinklr AI helps triage roughly four million inbound messages per year and reports measurable reductions in first response time and agent effort as part of its scaled social care operations.
This is the difference between “AI as a reply generator” and “AI as a detection + routing engine.”
Customer service problem-solving examples
Now that you understand the strategies used to solve customer service problems, let’s look at a few recent real-world examples that show these principles in action:
1. When leadership steps in early to prevent a pattern
Another trend Shep Hyken shares in their 2026 CX predictions is: “Customers will expect companies to value and respect their time.” This recent incident proves this well.
A former employee of India’s famous food delivery brand, Zomato, posted on X, criticizing the brand’s heavy reliance on bots and the difficulty customers face in reaching human support.
Instead of issuing a generic PR statement, Zomato’s CEO, Deepinder Goyal, responded directly on the same thread, acknowledging the concern, clarifying that “brands should always have human support,” and initiating an internal review of the boundaries of automation.
This is a clear case of acting at the signal stage, not the symptom stage. By treating one viral complaint as an early indicator of a larger trust issue, Zomato applied the Problem Lifecycle mindset and ensured the issue received absolute ownership before it escalated into a recurring CX pattern.
2. Protecting frontline experience before it becomes a CX crisis
When Montmorency Bakehouse in Melbourne went viral on TikTok, staff began receiving inappropriate comments and privacy invasions. The owners posted a direct video asking people to stop, clarified boundaries, and enforced stricter moderation. This proactive move, based on external social signals, protected staff and customer experience before it escalated into a crisis.
This reflects proactive problem detection, acting on external social signals before the issue turns into employee burnout or public backlash. It aligns with predictive CX, where brands monitor sentiment outside traditional support channels and intervene early to protect both staff and customer experience.
3. Automating routine failures before they hit agents
Facing high volumes of routine inquiries (shipment status, address confirmation), Aramex deployed an AI-powered WhatsApp chatbot integrated with backend systems. The bot handles these scenarios end-to-end, now managing 99% of such cases, deflecting millions of inquiries annually, and saving over a million agent hours while improving accuracy.
That’s the difference between deflection and design. Aramex re-engineered how routine issues move through the system; proving that real service transformation starts when humans stop solving problems machines can prevent.
Problem-solving skills every customer service professional needs
To build trust at scale, agents need future-focused skills. Below is a table outlining these essential capabilities:
Customer service problem-solving skills | What it means for your enterprise |
Signal literacy and pattern detection | Agents identify early warnings (e.g., repeated checkout failures from the same device) and escalate them before they become systemic. This helps engineering resolve issues earlier and reduces repeat contacts. |
AI copilot fluency | Agents work with AI tools that summarize histories and propose actions, validating AI logic for sensitive processes (like refunds) to ensure accuracy while speeding up resolution. |
Journey reconstruction and context stitching | Agents rebuild fragmented customer journeys across chat, email, and product logs. Seeing a customer's multiple login attempts leads to faster diagnosis and avoids repetition. |
Policy shaping and exception design | Agents recognize when a policy causes recurring frustration (e.g., a verification step that fails for international travelers) and collaborate with legal/product teams to design safe exceptions. |
Emotional calibration in AI-assisted conversations | Agents judge when a customer's frustration signals the need for a human-led resolution, stepping in to rebuild trust rather than letting automation continue. |
Cross-functional ownership and follow-through | Agents identify early warnings (e.g., repeated checkout failures from the same device) and escalate them before they become systemic. This helps engineering resolve issues earlier and reduces repeat contacts. |
Let automation do the heavy lifting so you can focus on progressing
The strategies we’ve discussed are not meant to overload your teams or drain their bandwidth. They exist so enterprises can stop firefighting and start advancing.
Gartner predicts that Agentic AI will autonomously resolve 80% of common customer service issues by 2029. The opportunity ahead is clear: let machines do the repetitive, high-volume work so humans can focus on judgment, empathy, and innovation.
With a balanced human-in-the-loop approach, the next step is to adopt AI agents that are built specifically for your enterprise workflows, brand standards and customer expectations.
Sprinklr has recognized this need across industry leaders and therefore provides flexible, customizable AI agents that seamlessly integrate with your existing operations, requiring minimal technical skills. This allows every CX leader with a forward-looking vision to harness agentic AI and scale customer service even as challenges evolve and customer expectations rise.
Book a demo and let our specialists guide you with the first step.
Frequently Asked Questions
Reactive teams respond to symptoms as they appear. Proactive teams detect early signals, investigate patterns, assign ownership and provide outside support, ultimately fixing the underlying system flaw. They prevent volume instead of managing it.
Top brands track recurrence rates, pattern resolution time, reduction of systemic issues, cross-functional fixes delivered, and customer friction removed from the journey. These metrics indicate whether problems are being resolved or simply answered more quickly.
Because staffing is not the root cause; recurrence occurs when no single owner is accountable, tagging is inconsistent or product and policy teams fail to recognize the diagnostic patterns surfacing in support queues.
Culture determines whether teams conceal issues or address them promptly. Top brands reward problem solvers, not just problem finders. They normalize escalation, reduce blame, and make cross-team fixes part of performance goals.
Investigation-focused AI clusters complaints, correlates logs and behavior data and flags early failure signatures long before volume spikes. This gives enterprises time to identify and fix the root cause, rather than waiting for customers to flood support.
